OpenCV Praxis: OCR für den Stromzähler

OpenCV (Open Computer Vision) ist eine leistungsfähige und komfortable Umgebung für die Realisierung vielfältiger Projekte im Bereich der Bildverarbeitung. Das vorliegende Tutorial stellt einige Aspekte von OpenCV anhand einer praktischen Anwendung vor - dem Auslesen eines Stromzählers.
In vielen Haushalten befinden sich noch Stromzähler mit einem mechanischen Zählwerk, die keine direkte, genormte Schnittstelle für das Auslesen der verbrauchten elektrischen Energie mittels eines Computers bereitstellen. Eine Möglichkeit, dennoch an diese Daten zu gelangen, besteht in der optischen Erfassung des Zählerstandes mit einer Videokamera und der anschließenden Zeichenerkennung (OCR - Optical Character Recognition). Das Tutorial beschreibt die Realisierung dieses Anwendungsfalls mit OpenCV. Das im Endeffekt entstehende Programm läuft sogar auf einem Raspberry Pi.
Inhalt
- Inhalt
- Workflow
- Installation von OpenCV
- Bilderfassung
- cv::Mat
- Bildverarbeitung
- Rotation
- Erkennung von Kanten und Linien
- Konturen
- Maschinelles Lernen
- Persistenz
- Plausibilitätsprüfung
- Datenspeicherung und -auswertung
- Hauptprogramm
- Fazit
- Interessante Links
Workflow
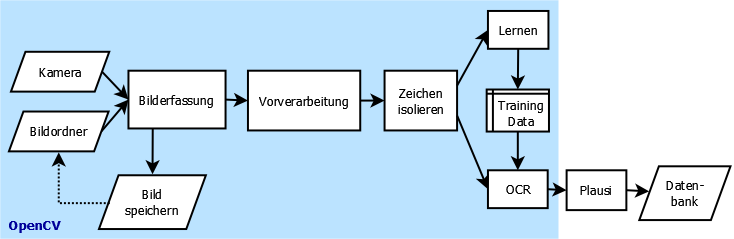
Abb. 1 zeigt den grundsätzlichen Programmablauf. Am Anfang steht die Aufnahme eines Bildes vom Stromzähler in festgelegten Intervallen durch eine Videokamera. Nach der Bilderfassung kann das Programm alternativ das Bild im Dateisystem abspeichern und später von dort wieder einlesen. Das ist zum Entwickeln und Testen sehr hilfreich, da man dann nicht immer auf eine angeschlossene Kamera angewiesen ist.
Das Bild durchläuft als nächstes eine Vorverarbeitung. Sie soll das Bild soweit verändern und optimieren, dass im nächsten Schritt die Detektion und Isolation der einzelnen Stellen des Zählwerks aus dem Bild möglich ist.
Die aus dem Bild extrahierten Zahlen gelangen dann in die Zeichenerkennung (OCR). Sie muss man allerdings zuerst mit einem Satz aller möglichen Zeichen (also den Ziffern 0 bis 9) interaktiv anlernen. Dabei entsteht ein Satz von Trainingsdaten, der in einer Datei gespeichert wird. Der OCR lädt im normalen Betrieb diesen Trainingsdatensatz und kann damit ein unbekanntes Zeichen klassifizieren.
Diese Klassifizierung erfolgt mit einem gewissen Fehler. Vor einer Weiterverarbeitung ist es daher sinnvoll, die vom OCR erkannten Zählerstände einer Plausibilitätsprüfung zu unterziehen. Ist sie bestanden, dann gelangt der erfasste Wert zusammen mit der aktuellen Uhrzeit in eine Datenbank. Mit den hier gespeicherten Daten kann man später Auswertungen vornehmen, wie die Erzeugung einer Grafik mit dem stündlichen, täglichen und wöchentlichen Stromverbrauch. Plausibilitätsprüfung und Datenbank sind nicht mit OpenCV implementiert, finden jedoch der Vollständigkeit halber ebenfalls Erwähnung in diesem Tutorial.
Installation von OpenCV
OpenCV ist Bestandteil vieler Linux Distributionen, insbesondere auch von Raspbian, Debian und Ubuntu. Die Laufzeitkomponenten stehen hier als dynamische Libraries zur Verfügung und sind über den Paketmanager installierbar. Der Entwickler von OpenCV-Programmen kann im Wesentlichen zwischen C++ und Python als Programmiersprache wählen. Dieses Tutorial verwendet C++ und setzt damit eine unter Linux funktionierende C++ Entwicklungsumgebung sowie die entsprechenden Grundkenntnisse in der Softwareentwicklung mit C++ voraus.
Auf Debian-basierten Distributionen erfolgt die Installation der für die Entwicklung von OpenCV C++-Programmen benötigten Komponenten mittels
apt-get install libopencv-dev
Dazu benötigt man Root-Rechte, die in der Regel mittels eines vorgeschalteten sudo zu erlangen sind. Die so installierte Version ist nicht die allerneueste, welche man von OpenCV Downloads beziehen kann. Für dieses Tutorial ist allerdings nur die Version 2.3.1 Voraussetzung, daher sollte die über den Packagemanager einer aktuellen Linuxdistribution installierte Version völlig ausreichen. Die Software wurde gegen OpenCV 2.3.1 (auf Debian wheezy), 2.4.1 (Raspbian) und 2.4.8 (Ubuntu 14.04) getestet.
Obwohl das fertige Programm auf einem Raspberry Pi läuft, empfiehlt sich für Entwicklung und Test die Verwendung eines leistungsfähigeren Computers, da sonst das iterative Übersetzen und Ausprobieren des Quellcodes auf Dauer zu viel Zeit verschlingt. Als Betriebssystem ist dann eine Debian-basierte Distribution sinnvoll, da sie sich ähnlich wie Raspbian verhält.
Auf jeden Fall sollte man nach der Installation die OpenCV Dokumentationsseite besuchen und das Reference Manual für die passende Version herunterladen. Die Referenz für die neueste stabile Version steht auch online bereit.
Der Quelltext des im Rahmen dieses Tutorials entwickelten und voll funktionsfähigen Beispielprogramms steht als Projekt emeocv (Electric meter with OpenCV) auf Github zur Verfügung. Eine lokale Kopie erstellt man durch
git clone https://github.com/skaringa/emeocv.git
Das Programm benötigt zusätzliche Komponenten für das Logging (log4cpp) und die Datenspeicherung (RRDtool), die
apt-get install rrdtool librrd-dev liblog4cpp5-dev
installiert. Danach kann man das Compilieren und Linken des Programms versuchen:
cd emeocv make
Läuft das fehlerfrei durch, dann sind alle benötigten Komponenten an Bord.
Bilderfassung
Eine USB Webcam nimmt das Bild des Stromzählers auf (Abb. 2). Mit OpenCV lässt sich dieser Vorgang in zwei Zeilen kodieren. Ähnlich einfach ist das Einlesen eines Bildes aus einer Datei realisierbar. Da das Programm mit beiden Eingabemethoden umgehen soll, lohnt sich hier ein objektorientierter Ansatz. Wir definieren dazu eine Basisklasse ImageInput, die das Image und den Zeitstempel der Imageerfassung hält.
Für den vollständigen Code sei auf das oben erwähnte Git-Repository verwiesen, die abgekürzte Definition ist:
#include <opencv2/imgproc/imgproc.hpp> #include <opencv2/highgui/highgui.hpp> class ImageInput { public: virtual bool nextImage() = 0; virtual cv::Mat & getImage(); virtual time_t getTime(); virtual void saveImage(); protected: cv::Mat _img; time_t _time; };
Die abgeleiteten Klassen DirectoryInput und CameraInput implementieren jeweils die Methode nextImage(), die für das Einlesen des Bildes zuständig ist:
class DirectoryInput: public ImageInput { public: virtual bool nextImage(); }; class CameraInput: public ImageInput { public: CameraInput(int device); virtual bool nextImage(); private: cv::VideoCapture _capture; };
DirectoryInput kümmert sich um das Einlesen eines Bildes aus einer Datei, der essentielle OpenCV-Code ist:
bool DirectoryInput::nextImage() { // read image from file at path _img = cv::imread(path); return true; }
Das Erfassen eines Bildes mit der Kamera setzt die Existenz eines VideoCapture Objektes voraus. Der Konstruktor CameraInput öffnet dann mittels VideoCapture.open() den Eingabekanal zur Kamera. Parameter ist ihre laufende Nummer, bei nur einer Kamera am Rechner ist das die Null:
CameraInput::CameraInput(int device) { _capture.open(device); } bool CameraInput::nextImage() { // read image from camera bool success = _capture.read(_img); return success; }
Zu Testzwecken möchte man vielleicht das von der Kamera aufgenommene Bild in eine Datei abspeichern. Das erledigt die Methode saveImage der Basisklasse:
void ImageInput::saveImage() { //std::string path = ... if (cv::imwrite(path, _img)) { log4cpp::Category::getRoot() << log4cpp::Priority::INFO << "Image saved to " + path; } }
Eine weitere oft benötigte Funktion ist die Anzeige eines Bildes. Auch dafür stellt OpenCV einen Einzeiler bereit, ohne das sich der Entwickler mit betriebssystemspezifischen Eigenheiten herumschlagen muss:
cv::imshow("ImageProcessor", _img);
Das erste Argument ist der Name des Fensters. Damit kann man unterschiedliche Aufrufe von imshow in das gleiche Fenster laufen lassen. Für eine einfache Benutzerinteraktion steht waitKey zur Verfügung:
int key = cv::waitKey(30);
wartet 30 Millisekunden auf eine Benutzereingabe und liefert die gedrückte Taste zurück.
Mit diesen Methoden lässt sich bereits ein einfaches Programm erstellen, welches in definierten Intervallen ein Bild mit der Kamera aufnimmt, anzeigt und in eine Datei abspeichert:
ImageInput* pImageInput = new CameraInput(0); pImageInput->setOutputDir("images"); while (pImageInput->nextImage()) { pImageInput->saveImage(); cv::imshow("Image", pImageInput->getImage()); int key = cv::waitKey(1000); if (key == 'q') break; }
Als Kamera dient eine einfache USB Video Class (UVC) Webcam mit einer Auflösung von 640x480 Pixeln. Das ist für den vorliegenden Anwendungsfall völlig ausreichend. Eine höhere Auflösung dürfte in Bezug auf die Genauigkeit der Zeichenerkennung nicht viel bringen, verbraucht dann allerdings viel mehr Hauptspeicher und Rechenzeit für die Bildverarbeitung, was gerade auf dem Raspberry Pi sehr begrenzte Ressourcen sind.
Viel Aufmerksamkeit muss man dem Thema Beleuchtung widmen. Da sich der Stromzähler im Keller in einem Schrank befindet, ist eine künstliche Beleuchtung erforderlich. Dabei hat selbstverständlich ein sparsamer Energieverbrauch höchste Priorität. Im Projekt kommt ein flexibler LED-Leuchtstreifen mit einem Verbrauch von etwa 1,5 Watt zum Einsatz, den ein Steckernetzteil mit 12 Volt Gleichspannung speist.
Das Licht darf man keinesfalls direkt auf den Stromzähler richten. Das führt unweigerlich zu Reflexionen auf der Abdeckscheibe, die eine spätere Bildverarbeitung erschweren oder ganz unmöglich machen, wenn sie zum Beispiel genau auf einer Ziffer des Zählers liegen und diese überstrahlen. Bewährt hat sich der Einsatz eines Diffusors zwischen Lichtquelle und Zähler. Dafür verwende ich Teile eines ausgedienten Plastikkanisters. Sein milchigweißes, halbdurchlässiges Material eignet sich gut zur Erzeugung einer diffusen Beleuchtung.
cv::Mat
An dieser Stelle lohnt ein kurzer Blick auf die Art und Weise, wie OpenCV ein Bild speichert. Sowohl imread() zum Lesen eines Bildes aus einer Datei als auch VideoCapture.read() für das Holen des Kamerabildes produzieren ein Objekt vom Typ cv::Mat.
Der Namespaceprefix cv kapselt alle Klassen und Funktionen von OpenCV, um Namenskollisionen mit anderen Bibliotheken zu vermeiden. Mat ist ein n-dimensionales Array oder eine Matrix, die zum Speichern der unterschiedlichsten Dinge genutzt werden kann. Ein wichtiges Merkmal ist dabei die eingebaute Speicherverwaltung. Man kann Objekte vom Typ cv::Mat beliebig kopieren und wiederverwenden, ohne sich um die Allokation oder Freigabe von Speicher kümmern zu müssen. Insbesondere ist das Kopieren auch eine sehr billige Operation, da in Wirklichkeit nur ein Referenzzähler inkrementiert wird, anstatt den kompletten Speicherbereich zu duplizieren. Benötigt man doch einmal eine echte Kopie eines Mat-Objektes, dann ist seine Memberfunktion clone() zu verwenden.
In unserem Beispiel enthält das Mat-Objekt _img das eingelesene beziehungsweise aufgenommene Bild. Standardmäßig produzieren imread() und VideoCapture.read() Bilder im BGR (blue-green-red) Farbraum. Dieser ist identisch zum bekannten RGB Farbmodell, nur mit einer invertierten Anordnung der Farbkanäle im Speicher. Das Modell beschreibt jedes Pixel des Bildes mit drei unabhängigen Intensitätswerten für Blau, Grün und Rot.
Ein weiteres oft verwendetes Farbmodell ist Grayscale (Graustufen), welches jedes Pixel mit einem einzigen Grauwert kodiert. In diesem Fall ist cv::Mat eine zweidimensionale Matrix, während sie beim BGR Farbraum dreidimensional ist. Die Zuordnung eines Bild zu einem der beiden Farbmodelle gelingt mit der Funktion channels(). Sie liefert den Wert drei für BGR beziehungsweise eins für Grayscale zurück.
Eine oft benötigte Funktion ist die Umwandlung eines BGR Bildes in Graustufen. Dazu dient die Methode cvtColor:
cv::Mat color, gray; color = cv::imread(filename); cvtColor(color, gray, CV_BGR2GRAY);
Bildverarbeitung

Ein Schnappschuss des Stromzählers befindet nun in einem cv::Mat Objekt. Bevor wir uns an die Zeichenerkennung des Zählerstandes wagen können, muss der Algorithmus zunächst die einzelnen Ziffern des Zähler im Bild identifizieren und extrahieren. Betrachten wir dazu ein mit der Kamera aufgenommenes Bild des Stromzählers (Abb. 2): Was unserem lebenslang trainierten Hirn mit Leichtigkeit gelingt, ist für den «ungelernten» Computer ein riesiges Problem. Welches Kriterium unterscheidet das Zeichen «0» des mechanischen Zählers von der «0» in der Frequenzangabe 50 Hz? Einen möglichen Algorithmus zur Extraktion der relevanten Information aus dem Bild wollen wir im folgenden erarbeiten.
Die Klasse ImageProcessor kapselt alle dazu erforderlichen Methoden. Ihre abgekürzte Definition lautet:
class ImageProcessor { public: void setInput(cv::Mat & img); void process(); const std::vector<cv::Mat> & getOutput(); private: cv::Mat _img; cv::Mat _imgGray; std::vector<cv::Mat> _digits; };
Mit setInput() übergibt man das zu verarbeitende Bild. Die Funktion process() nimmt die komplette Verarbeitung vor. Nach Durchlauf von process() liefert getOutput() das Ergebnis zurück. Es besteht aus einem Vektor von Bildern. Jedes Bild enthält ein Zeichen des Zählwerks. War der Algorithmus erfolgreich, dann müsste die Länge des Vektors genau sieben betragen.
Die Funktion process() delegiert die einzelnen Verarbeitungsschritte an weitere private Funktionen. Der Ablauf ist für jedes Bild der gleiche:
- Umwandlung in ein Graustufenbild
- Rotation, sodass die Ziffern des Zählwerks auf einer waagerechten Linie liegen
- Lokalisieren und Ausschneiden der einzelnen Ziffern
void ImageProcessor::process() { _digits.clear(); // convert to gray cvtColor(_img, _imgGray, CV_BGR2GRAY); // initial rotation to get the digits up rotate(_config.getRotationDegrees()); // detect and correct remaining skew (+- 30 deg) float skew_deg = detectSkew(); rotate(skew_deg); // find and isolate counter digits findCounterDigits(); }
Rotation
Nach der Umwandlung des Bildes in Graustufen soll der Algorithmus das Bild soweit rotieren, dass die sieben Ziffern des Zählers auf einer waagerechten Linie liegen. Danach fällt ihre Identifikation wesentlich leichter: Sieben waagerecht angeordnete, helle Konturen.
Die Rotation eines Bildes erledigt die Funktion cv::warpAffine() mittels einer affinen Transformation. Das sind - vereinfacht gesagt - solche Veränderungen des Bildes, bei denen alle parallelen Linien auch nach der Transformation noch parallel sind. Dazu gehören Verschiebung (Translation), Drehung (Rotation) und Größenänderung (Skalierung). Alle diese Transformationen lassen sich mit Hilfe einer Transformationsmatrix beschreiben. Bei einer Vielzahl von aufeinanderfolgenden affinen Transformationen des gleichen Bildes ist es aus Performancegründen oft sinnvoll, zunächst die einzelnen Transformationsmatrizen schrittweise zu multiplizieren und erst ganz zum Schluss die eigentliche Transformation des Bildes vorzunehmen.
Die Rotation des Bildes um einen vorgegebenen Winkel lagern wir in die Funktion rotate() aus:
void ImageProcessor::rotate(double rotationDegrees) { cv::Mat M = cv::getRotationMatrix2D( cv::Point(_imgGray.cols / 2, _imgGray.rows / 2), rotationDegrees, 1); cv::Mat img_rotated; cv::warpAffine(_imgGray, img_rotated, M, _imgGray.size()); _imgGray = img_rotated; }
Zur Konstruktion der Rotationsmatrix ist neben dem Winkel der Drehpunkt erforderlich. Dazu berechnet man den Mittelpunkt des Bildes aus der Anzahl seiner Spalten (cols) und Zeilen (rows).
Damit haben wir das Werkzeug zur Hand, um das Bild gerade auszurichten. Was noch fehlt, ist die Bestimmung des Drehwinkels. Das soll in zwei Schritten erfolgen. Der Grund dafür liegt in der mechanischen Konstruktion der Kameraaufhängung:
Die USB Webcam hat eine Klammer zur Befestigung an einem Stativ und ein Kugelgelenk, welches das Schwenken um alle drei Raumachsen in gewissen Grenzen erlaubt. Mittels der Klammer ist die Kamera an einem vertikalen Stab befestigt. Das führt dazu, dass alle aufgenommenen Bilder prinzipiell um 90 Grad entgegen dem Uhrzeigersinn gedreht sind. Diese konstruktionsbedingte Drehung kann man als erstes durch Angabe eines festen Winkels rückgängig machen:
// initial rotation to get the digits up
rotate(_config.getRotationDegrees());
Der erforderliche Winkel ist konfigurierbar. Den Zugriff auf die Konfiguration kapselt das _config Objekt - dazu später mehr. Im Beispiel muss der Winkel 270° (entspricht -90°) betragen, um die konstruktionsbedingte Drehung auszugleichen.
Danach sind die Zählerstellen immer noch nicht exakt waagerecht ausgerichtet. Das liegt an der Einstellung des Kugelgelenks. Zwar könnte man versuchen, durch Drehen des Gelenks bei ständiger visueller Kontrolle des aufgenommenen Bildes die Kamera exakt auszurichten. Das ist aber wahrscheinlich ein zeitaufwändiges und nervendes Unterfangen. Besser wäre es, wenn wir den verbleibenden Ausrichtungsfehler per Software detektieren und ausgleichen könnten!
Erkennung von Kanten und Linien
Unser Auge orientiert sich beim Ablesen des Zählerstandes (zum Beispiel aus Abb. 2) nicht an absoluten Helligkeits- oder Farbwerten. Die Ganglienzellen in der Netzhaut sind vielmehr so verdrahtet, dass sie auf einen hohen Kontrast reagieren. Damit ist es dem Hirn möglich, Kanten, Linien und daraus die äußere Form des Zählers und die einzelnen Ziffern sehr schnell bei den unterschiedlichsten Helligkeiten zu erkennen.
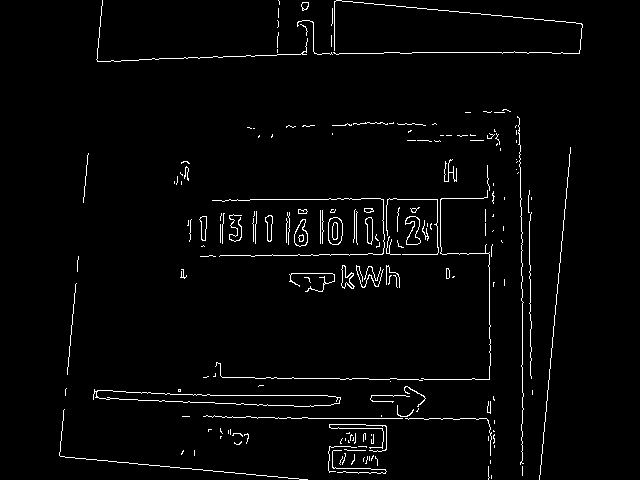
Folgerichtig ist daher der Identifikation von Kanten und Linien ein großer Teil von OpenCV gewidmet. Eine in vielen Situationen brauchbare Routine ist der Canny Algorithmus. Canny() bekommt als Input das Graustufenbild und liefert als Ausgabe edges ein Bild mit den erkannten Kanten ähnlich Abb. 3:
/** * Detect edges using Canny algorithm. */ cv::Mat ImageProcessor::cannyEdges() { cv::Mat edges; // detect edges cv::Canny(_imgGray, edges, _config.getCannyThreshold1(), _config.getCannyThreshold2()); return edges; }

Die beiden threshold-Parameter von Canny hängen von der Beleuchtung und dem damit erzielten Kontrast ab und sind daher in eine Konfigurationsdatei ausgelagert. Bilder mit hohem Kontrast erfordern hohe threshold-Werte. Für Abb. 2 kamen die Werte 200 und 250 zur Anwendung. Eine alternativ getestete Beleuchtungssituation erzeugte Bilder mit niedrigerem Kontrast (Abb. 4), hier führen dann die Werte 100 und 200 zum Ziel. Man muss an dieser Stelle etwas herumprobieren, um die optimalen Parameter zu finden.
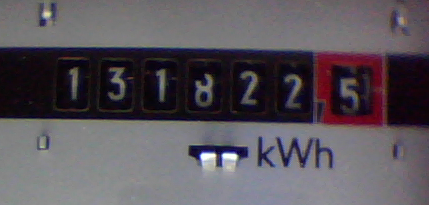
Im Kantenbild sind die unwichtigen Details jetzt größtenteils verschwunden. Alle für den Prozess relevanten Informationen sind aber noch vorhanden: Zum einen die sieben Zählerziffern, um die wir uns später kümmern. Zum anderen sind aber auch diverse parallele Linien erkennbar, zum Beispiel die Begrenzungen von Zählergehäuse, Zählwerk und Zählring. Die Abweichung dieser Linien zur Horizontalen ist genau der Winkel, den man zur Ausrichtung des Bildes benötigt.
Das, was unser Auge sofort als Linie erkennt, ist für OpenCV allerdings erst einmal nur eine Anordnung heller Pixel auf schwarzem Grund. Um daraus Linien zu identifizieren, führt man als nächstes eine Hough Transformation mittels cv::HoughLines() durch:
/** * Detect the skew of the image by finding almost (+- 30 deg) horizontal lines. */ float ImageProcessor::detectSkew() { cv::Mat edges = cannyEdges(); // find lines std::vector<cv::Vec2f> lines; cv::HoughLines(edges, lines, 1, CV_PI / 180.f, 140);
Der hier fest einprogrammierte Schwellwert von 140 ist die Anzahl von Voten, die eine Kante zur Identifikation als Linie benötigt. Je größer der Wert ist, desto länger muss die zusammenhängende Linie sein. Beobachtet man Ungenauigkeiten bei der Bestimmung des Winkels in detectSkew(), dann ist es sinnvoll, zuerst mit diesem Wert zu experimentieren.
HoughLines() liefert den Vektor lines zurück, der alle erkannten Linien enthält. Jedes Element von lines ist wiederum ein Vektor mit zwei Elementen. Das erste Element ist der Abstand der Linie von der oberen linken Ecke des Bildes, das zweite der Winkel gegenüber der Vertikalen.
Dieser Winkel ist genau das, was wir brauchen. Aber von welcher Linie? Es sind ja wahrscheinlich auch die senkrechten Linien im Ergebnis enthalten. Limitiert man den maximal ausgleichbaren Drehfehler auf ±30°, dann kann man mit diesem Kriterium nun alle interessierenden Linien ausfiltern und den Durchschnitt über ihre Winkel bilden. Dabei ist noch zu beachten, dass HoughLines() die Winkel in Radiant liefert, während rotate() den Drehwinkel in Grad benötigt. Abb. 5 zeigt das damit endgültig ausgerichtete Kamerabild mit den zur Winkelbestimmung verwendeten Linien.
// filter lines by theta and compute average
std::vector<cv::Vec2f> filteredLines;
float theta_min = 60.f * CV_PI / 180.f;
float theta_max = 120.f * CV_PI / 180.0f;
float theta_avr = 0.f;
float theta_deg = 0.f;
for (size_t i = 0; i < lines.size(); i++) {
float theta = lines[i][1];
if (theta > theta_min && theta < theta_max) {
filteredLines.push_back(lines[i]);
theta_avr += theta;
}
}
if (filteredLines.size() > 0) {
theta_avr /= filteredLines.size();
theta_deg = (theta_avr / CV_PI * 180.f) - 90;
}
return theta_deg;
}

Konturen
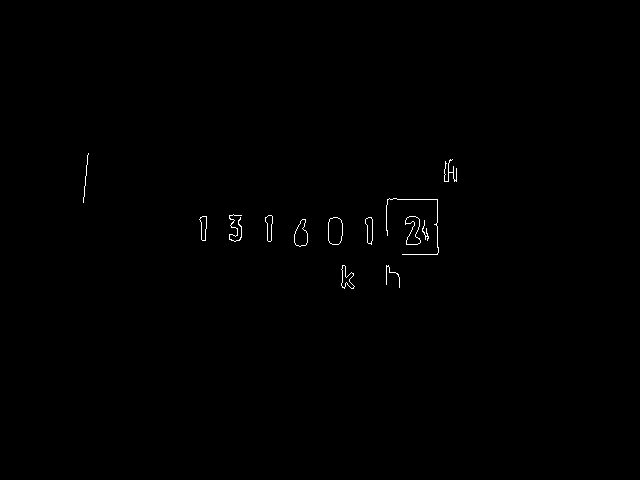
Nun kann es an die Identifizierung und Extraktion der einzelnen Ziffern des Zählerwerks gehen. Ausgangspunkt sind die wiederum mit Canny() aus dem geradegerichteten Bild gewonnenen Kanten (Abb. 6).
Zur Erkennung der Ziffern verwendet man die Konturenerkennung von OpenCV, die in findContours() implementiert ist. Da diese Funktion die übergebene Bildmatrix verändert, legt man vorher noch per clone() eine Kopie des Kantenbildes in img_ret an:
/** * Find and isolate the digits of the counter, */ void ImageProcessor::findCounterDigits() { // edge image cv::Mat edges = cannyEdges(); cv::Mat img_ret = edges.clone(); // find contours in whole image std::vector<std::vector<cv::Point> > contours, filteredContours; std::vector<cv::Rect> boundingBoxes; cv::findContours(edges, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
Die gefundenen Konturen stehen im Vektor contours. Jedes Element repräsentiert eine einzelne Kontur, die als Vektor von Punkten definiert ist. Der Parameter CV_RETR_EXTERNAL weist findContours() an, nur die äußeren Begrenzungen von Konturen zurückzuliefern.
Aus dem Ergebnis, welches jetzt noch alle möglichen Konturen enthält, müssen wir nun die interessierenden Ziffern herausfiltern. Das erfolgt in zwei Schritten: Zunächst filtern wir die Konturen nach der Größe ihrer Bounding Box:
// filter contours by bounding rect size
filterContours(contours, boundingBoxes, filteredContours);
Die Funktion filterContours() (vollständiger Quellcode im GitRepo) iteriert über den contours-Vektor und ruft für jedes Element die Funktion cv::boundingRect() auf. Sie liefert ein Objekt vom Typ cv::Rect zurück, welches das Rechteck der äußeren Umfassung der Kontur beschreibt. Der Algorithmus inspiziert dann Höhe und Breite der Bounding Box. Die Höhe muss innerhalb vorgegebener, konfigurierbarer Grenzen liegen, und immer größer als ihre Breite sein. Abb. 7 zeigt das Ergebnis der Filterung.
Es sind jetzt nur noch sehr wenige Störungen neben den nutzbaren Ziffern enthalten. Um letztere zu identifizieren, werten wir im zweiten Schritt die y-Positionen und Höhen der berechneten Bounding Boxes aus. Der Algorithmus probiert dazu alle möglichen Kombinationen von Bounding Boxes aus, um die größte Anzahl von gleich großen Konturen auf einer horizontalen Linie zu finden. Der Ergebnisvektor alignedBoxes enthält dann mit großer Wahrscheinlichkeit die Bounding Boxes der einzelnen Ziffern, da keine andere Gruppierung von Konturen derart signifikant ausgerichtet ist.
// find bounding boxes that are aligned at y position
std::vector<cv::Rect> alignedBoundingBoxes, tmpRes;
for (std::vector<cv::Rect>const_iterator ib = boundingBoxes.begin();
ib != boundingBoxes.end(); ++ib) {
tmpRes.clear();
findAlignedBoxes(ib, boundingBoxes.end(), tmpRes);
if (tmpRes.size() > alignedBoundingBoxes.size()) {
alignedBoundingBoxes = tmpRes;
}
}
Damit das Ergebnis die Ziffern in ihrer Anordnung von links nach rechts enthält, folgt eine Sortierung der Bounding Boxes nach ihrer x-Position:
// sort bounding boxes from left to right
std::sort(alignedBoundingBoxes.begin(), alignedBoundingBoxes.end(), sortRectByX());
Mit diesen Informationen kann man nun die einzelnen Ziffern aus dem Bild herausschneiden. Dafür ist Operator () von cv::Mat zuständig, der die «Region of interest» (ROI) als Parameter übergeben bekommt. Wahlweise zeichnet dann noch cv::rectangle() die erkannten Regionen als grüne Boxen in das Originalbild (Abb. 7) - das ist bei der Justierung von Kamera und Lichtquelle sehr hilfreich.
// cut out found rectangles from edged image
for (int i = 0; i < alignedBoundingBoxes.size(); ++i) {
cv::Rect roi = alignedBoundingBoxes[i];
_digits.push_back(img_ret(roi));
if (_debugDigits) {
cv::rectangle(_img, roi, cv::Scalar(0, 255, 0), 2);
}
}
}

Maschinelles Lernen
Die ausgeschnittenen Ziffern im Vektor _digits enthalten jeweils das Kantenbild einer einzelnen Ziffer (Abb. 8).

Mittels einer optischen Zeichenerkennung (OCR) gewinnt der Computer aus diesen Bildern die Information, um welches Zeichen es sich handelt. Eine oft dafür verwendete Technik ist das maschinelle Lernen. Dazu trainiert man in einem ersten Schritt das System mit einer Vielzahl von Testdaten. Dabei entsteht ein Modell, welches eine für den Computer verständliche Abbildung von Daten (hier: Bildern) in Information (hier: Zeichenkodierungen) enthält. Mit Hilfe dieses Modells kann das angelernte System dann im weiteren Verlauf für unbekannte Daten eine Transformation in die gewünschte Information vornehmen.
Es gibt eine Vielzahl von Algorithmen für das maschinelle Lernen, von denen OpenCV einen großen Teil implementiert. Die Auswahl des richtigen Algorithmus für eine konkrete Problemstellung verlangt sehr viel Erfahrung und Kenntnisse. Im folgenden soll einer der einfachsten Algorithmen zur Anwendung kommen: K-nearest neighbors. Er ist dafür bekannt, einerseits sehr genau zu sein und andererseits relativ viel Rechenzeit und Speicher zu verbrauchen. Diese Nachteile sind für unseren Anwendungsfall nicht so entscheidend - Zeit ist ausreichend vorhanden, da sich das Zählwerk nicht rasend schnell dreht. Speicher ist auf dem Raspberry Pi zwar limitiert, allerdings sollte er für die überschaubare Größe des Modells ausreichen, das ja nur zehn Ziffern erkennen soll.
Für die Implementierung von Training und Zeichenerkennung ist die Klasse KNearestOcr zuständig:
class KNearestOcr { public: int learn(const cv::Mat & img); char recognize(const cv::Mat & img); void saveTrainingData(); bool loadTrainingData(); private: cv::Mat prepareSample(const cv::Mat & img); void initModel(); cv::Mat _samples; cv::Mat _responses; CvKNearest* _pModel; };
Die Routinen für das maschinelle Lernen können mit vielerlei Eingangsdaten - nicht nur mit Bildern - arbeiten. Die Aufbereitung dieser Daten bezeichnet man auch als «Feature Extraction». Dabei ist als erstes darauf zu achten, dass ausschließlich für den Lernprozess relevante Daten in den Prozess gelangen. Das hat die Vorverarbeitung in ImageProcessor schon sehr gut erledigt: Es liegen die von Hintergrund und Farbe befreiten und zugeschnittenen Konturen der Ziffern vor. Die Feature Extraction kann daher an dieser Stelle sehr einfach erfolgen: Zuerst bringt man alle Ziffernbilder mit cv::resize() auf die einheitliche Größe von 10x10 Pixeln. Da K-nearest neighbors mit eindimensionalen Vektoren aus Floating-Point Zahlen arbeitet, konvertieren die Funktionen reshape() und convertTo() die Bildmatrix in dieses Format:
/** * Prepare an image of a digit to work as a sample for the model. */ cv::Mat KNearestOcr::prepareSample(const cv::Mat& img) { cv::Mat roi, sample; cv::resize(img, roi, cv::Size(10, 10)); roi.reshape(1, 1).convertTo(sample, CV_32F); return sample; }
Die Anlernroutine baut dann die zwei Felder _samples und _responses auf. In _samples stehen alle Features (das Resultat von prepareSample), die den Trainingsprozess erfolgreich durchlaufen haben. Das gleichlange Feld _responses enthält die zu jedem Feature gehörende «Antwort» des Trainers - also die entsprechende Ziffer. Die Implementierung der interaktiven Trainingsroutine gestaltet sich erstaunlich einfach:
/** * Learn a single digit. */ int KNearestOcr::learn(const cv::Mat & img) { cv::imshow("Learn", img); int key = cv::waitKey(0); if (key > '0' && key < '9') { _responses.push_back(cv::Mat(1, 1, CV_32F, (float) key - '0')); _samples.push_back(prepareSample(img)); } return key; }
Zuerst zeigt cv::imshow() das Bild der Ziffer an. Dann wartet cv::waitKey() die Eingabe des Trainers ab. War diese eine gültige Ziffer, dann wird sie zusammen mit dem zugehörigen Feature nach _responses und _samples geschrieben.
Der Benutzer kann den Trainingsprozess jederzeit mit den Tasten 'q' oder 's' beenden (siehe auch learnOcr() in main.cpp). Im Falle von 's' schreibt die Funktion saveTrainingData() die Felder _samples und _responses in eine Datei. Darauf gehen wir im Abschnitt Persistenz weiter unten noch detailliert ein.
Während des regulären Betriebs lädt als erstes KNearestOcr::loadTrainingData() diese Datei und initialisiert damit das Modell:
/** * Initialize the model. */ void KNearestOcr::initModel() { _pModel = new CvKNearest(_samples, _responses); }
Das Modell ist jetzt in der Lage, beliebige, durch prepareSample() vorbereitete Bilder dadurch zu klassifizieren, indem es das am nächsten liegende Feature bestimmt und die zugehörige, angelernte Response zurückliefert.
Unsere recognize() Routine geht sogar noch etwas weiter: Sie ermittelt mittels find_nearest() die zwei nächsten Nachbarn und deren Distanz zum angelernten Original. Nur wenn beide Werte übereinstimmen und die Distanz unterhalb eines Schwellwerts liegt, gibt die Funktion ein gültiges Zeichen zurück. Der Bestimmung des konfigurierbaren Schwellwertes ocrMaxDist sollte man durchaus etwas Zeit widmen. Zu kleine Werte führen zur Zurückweisung eigentlich korrekt erkannter Werte und es kommt zu längeren Lücken in den erfassten Daten. Ein zu hoher Wert produziert dagegen zu viele Fehler in den Ergebnissen. Für meine konkrete Umgebung habe ich mit dem Wert 600000 ein Optimum gefunden.
/** * Recognize a single digit. */ char KNearestOcr::recognize(const cv::Mat& img) { char cres = '?'; cv::Mat results, neighborResponses, dists; float result = _pModel->find_nearest( prepareSample(img), 2, results, neighborResponses, dists); if (0 == int(neighborResponses.at<float>0, 0) - neighborResponses.at<float>0, 1)) && dists.at<float>0, 0) < _config.getOcrMaxDist()) { cres = '0' + (int) result; } return cres; }
Persistenz
Das Programm benötigt an verschiedenen Stellen die Möglichkeit, Daten persistent im Dateisystem zu speichern und wieder von dort zu laden. Das sind das trainierte Modell für die Zeichenerkennung und eine Konfigurationsdatei mit verschiedenen Parametern. Als Anforderungen an die Persistenzschicht ergeben sich daraus zum einen der Umgang mit strukturierten Daten wie cv::Mat. Zum anderen soll die Konfigurationsdatei vom Benutzer in einem Texteditor einfach und intuitiv zu bearbeiten sein.
OpenCV stellt mit cv::FileStorage eine Schnittstelle bereit, die beide Anforderungen erfüllt. Sie erlaubt das Speichern und Laden der meisten in OpenCV eingebauten einfachen und komplexen Datentypen sowie von numerischen und textuellen Standard-C Datentypen. Als Dateiformat hat man XML oder YAML zur Auswahl, die Steuerung erfolgt über die Dateiextension. Für emeocv wählte ich YAML, da es kompakter und besser lesbar ist.
Das Lesen und Schreiben der Daten kann mit C++ Streams erfolgen. Dabei schreibt man zunächst einen textuellen Schlüssel und dann die Daten. Über den Schlüssel lassen sich die Daten beim Lesen dann wieder korrekt zuordnen. Das Speichern und Lesen der trainierten Daten in KNearestOcr erfordert so nur eine minmale Anzahl von Codezeilen:
/** * Save training data to file. */ void KNearestOcr::saveTrainingData() { cv::FileStorage fs(_config.getTrainingDataFilename(), cv::FileStorage::WRITE); fs << "samples" << _samples; fs << "responses" << _responses; fs.release(); } /** * Load training data from file and init model. */ bool KNearestOcr::loadTrainingData() { cv::FileStorage fs(_config.getTrainingDataFilename(), cv::FileStorage::READ); if (fs.isOpened()) { fs["samples"] >> _samples; fs["responses"] >> _responses; fs.release(); initModel(); } else { return false; } return true; }
Analog dazu funktioniert das Lesen der Konfigurationsdatei config.yml in der Klasse Config:
void Config::loadConfig() { cv::FileStorage fs("config.yml", cv::FileStorage::READ); if (fs.isOpened()) { fs["rotationDegrees"] >> _rotationDegrees; fs["digitMinHeight"] >> _digitMinHeight; // und so weiter } else { // no config file - create an initial one with default values saveConfig(); } }
Plausibilitätsprüfung
Wie in der recognize() Methode des OCR zu sehen war, trifft die Zeichenerkennung schon eine Entscheidung, ob der Erkennungsfehler eine bestimmte Schwelle unterschreitet. Ist er zu hoch, dann gibt recognize das Zeichen '?' zurück. Diese Prüfung ist allerdings manchmal nicht ausreichend. So kommt es durchaus vor, dass der OCR die Zeichen 0 und 8 verwechselt. Kritisch ist auch die Tatsache, dass die Ziffern des Zählwerks nicht definiert umschalten, sondern langsam von unten nach oben in das Zählfeld hineinrotieren. Ist dann zum Beispiel nur der obere Teil der Ziffer 2 sichtbar, dann ähnelt er der Ziffer 7 und es kommt zu Fehlerkennungen.
OCR Programme zur Erkennung von Texten behelfen sich an dieser Stelle mit einem Wörterbuch. Dieses erlaubt nicht nur den Ausschluss offensichtlich unsinniger Buchstabenkombinationen, sondern in vielen Fällen sogar eine automatische Korrektur. Leider versagt dieser Ansatz bei der Erkennung eines numerischen Zählerstandes - es gibt hierfür kein Wörterbuch.
Man kann jedoch auf andere Art und Weise ein Regelwerk aufstellen, um die Plausibilität der vom OCR gelieferten Zählerstände vor einer Weiterverarbeitung zu prüfen. Die Implementierung erfolgt in der Klasse Plausi. Sie verwendet kein OpenCV mehr, soll jedoch der Vollständigkeit halber hier erwähnt sein. Die implementierten Regeln sind:
- Ein Zählerstand besteht aus genau sieben gültigen Ziffern.
- Da sich der Zähler nie rückwärts dreht, darf der aktuelle Wert nicht kleiner als der vorhergehende sein.
- Bildet man die Differenz zwischen zwei Zählerständen und teilt sie durch die vergangene Zeit, dann erhält man die durchschnittliche Leistungsaufnahme . Diese Leistung kann nicht größer als der durch die Absicherung des Stromkreises vorgegebene Maximalwert sein. Ist zum Beispiel ein mit 220 Volt gespeister Haushalt mit einer 50 Ampere Sicherung geschützt, dann kann P nicht größer als 11 Kilowatt sein.
Um die Regeln 2. und 3. prüfen zu können, muss die Plausi Klasse den letzten Zählerstand und seinen Zeitstempel zwischenspeichern. In der Praxis hat sich dann gezeigt, dass die Betrachtung von nur zwei Werten manchmal noch nicht ausreicht und insbesondere Ausreißer nach oben produziert. Daher speichert Plausi stattdessen die letzten elf Werte in einer Queue zwischen. Nur wenn alle diese Werte den Plausibilitätsprüfungen genügen, wird der jeweils mittlere Wert der Queue weitergeleitet.
Datenspeicherung und -auswertung
Die Weiterverarbeitung der für gültig befundenen Zählerstände ist ebenfalls nicht mehr Thema von OpenCV. In meiner Anwendung habe ich mich dazu entschieden, Zählerstand und Energieverbrauch in einer Round Robin Datenbank zu speichern.
Eine sinnvolle zeitliche Auflösung der Verbrauchswerte variiert mit ihrem Alter: Die aktuellen Zahlen sollen möglichst genau - etwa pro Minute - aufgelöst sein. Im Wochenrückblick interessieren mich dagegen nur noch die kumulierten Tageswerte und für den Jahresverlauf sind Wochendurchschnittswerte durchaus ausreichend. Aus diesem Grund ist hier die Verwendung einer Round Robin Datenbank mit automatischer Wertekonsolidierung in Form von rrdtool das Mittel der Wahl.
Das Anlegen der Datenbank erfolgt mit dem Script create_rrd.sh:
rrdtool create emeter.rrd \ --no-overwrite \ --step 60 \ DS:counter:GAUGE:86400:0:1000000 \ DS:consum:DERIVE:86400:0:1000000 \ RRA:LAST:0.5:1:4320 \ RRA:AVERAGE:0.5:1:4320 \ RRA:LAST:0.5:1440:30 \ RRA:AVERAGE:0.5:1440:30 \ RRA:LAST:0.5:10080:520 \ RRA:AVERAGE:0.5:10080:520
Der Parameter --step 60 legt das grundlegende Zeitintervall auf 60 Sekunden = 1 Minute fest. Dann definiert man zwei Datenquellen DS: counter dient der Erfassung des Zählerstandes (das ist die verrichtete Arbeit W) und consum speichert die elektrische Leistung P. Da es von Typ DERIVE ist, nimmt es automatisch eine Differenzierung der zu speichernden Werte nach der Zeit vor.
Die Definitionen der Round Robin Archive (RRA) bestimmen Anzahl und Aufbewahrungszeit der Daten: Die erfassten Minutenwerte hebt man drei Tage (entsprechend 4320 Werten) auf, die konsolidierten Tageswerte 30 Tage lang und die Wochenwerte 520 Wochen (also etwa 10 Jahre).
Es sind jeweils zwei RRAs für jeden Zeitraum definiert. Sie unterscheiden sich in ihrer Konsolidierungsfunktion: Die Konsolidierung LAST ist für den Zählerstand zuständig, denn hier interessiert ja der letzte gemessene Wert. Beim Verbrauch hingegen will man nicht den letzten Wert, sondern den Durchschnitt wissen, weswegen hierfür die Funktion AVERAGE zum Zuge kommt.
Der Befehl legt die Datei emeter.rrd mit einer Größe von etwa 150 Kilobyte an. Da es sich um eine Round Robin Datenbank handelt, ändert sich die Größe nicht mehr - egal wie viele Daten man hineinpumpt!
Für das Schreiben des Zählerstandes in die Datenbank ist die Funktion update() aus der Klasse RRDatabase zuständig:
int RRDatabase::update(time_t time, double counter) { char values[256]; snprintf(values, 255, "%ld:%.1f:%.0f", (long)time, counter/* kWh */, counter * 3600000. /* Ws */); char *updateparams[] = { "rrdupdate", _filename, values, NULL }; rrd_clear_error(); int res = rrd_update(3, updateparams); return res; }
Die Funktion bekommt Zeitstempel und Zählerstand übergeben. Daraus konstruiert die snprintf() Anweisung einen Update Parameterstring für rrdtool. Die ersten beiden Parameter sind Zeitstempel und Zählerstand. Der dritte Parameter ist ebenfalls der Zählerstand. Er geht in die Datasource consum, die wir beim Anlegen der Datenbank als Typ DERIVE deklariert haben. Das heißt, sie differenziert den Zählerstand automatisch nach der Zeit, wobei als Zeiteinheit eine Sekunde dient. Da der Zählerstand die Einheit Kilowattstunden (kWh) hat, empfiehlt es sich, ihn vor dem Einfügen in Wattsekunden (Ws) umzurechnen. Damit steht in consum dann direkt die abgenommene (Durchschnitts-)Leistung in Watt.
Eine herausragende Eigenschaft von rrdtool ist die Möglichkeit zur direkten Erzeugung von Grafiken. Dazu muss die Datenerfassung natürlich erst einmal einige Stunden laufen. Dann lässt sich eine Grafik mit dem Verbrauchsverlauf der letzten 24 Stunden zum Beispiel so erzeugen:
rrdtool graph consum.gif \ -s 'now -1 day' -e 'now' \ -Y -A \ DEF:consum=emeter.rrd:consum:AVERAGE \ LINE2:consum#00FF00:W \ CDEF:conskwh=consum,24,*,1000,/ \ VDEF:conspd=conskwh,AVERAGE \ 'GPRINT:conspd:%.1lf kWh am Tag'
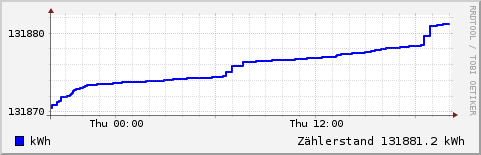
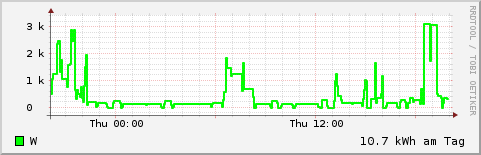
Weitere Beispiele finden sich im Unterverzeichnis www des Git-Repositories. Damit kann man eine minimale Webanwendung aufbauen, die Zählerstand und Verbrauchswerte für verschiedene Zeiträume mit Hilfe eines auf dem Raspberry Pi laufenden Webservers im Intranet zur Verfügung stellt. Hinweise dazu liefert der Artikel Gaszähler auslesen mit Magnetometer HMC5883 und Raspberry Pi.
Hauptprogramm
Das Hauptprogramm in der Datei main.cpp übernimmt die Koordinierung der beschriebenen Komponenten. Die Steuerung erfolgt über Kommandozeilenparameter, eine kurze Erklärung dazu gibt die Option -h aus:
Usage: emeocv [-i <dir>|-c <cam>] [-l|-t|-a|-w|-o <dir>] [-s <delay>] [-v <level>] Image input: -i <image directory> : read image files (png) from directory. -c <camera number> : read images from camera. Operation: -a : adjust camera. -o <directory> : capture images into directory. -l : learn OCR. -t : test OCR. -w : write OCR data to RR database. This is the normal working mode. Options: -s <n> : Sleep n milliseconds after processing of each image (default=1000). -v <l> : Log level. One of DEBUG, INFO, ERROR (default).
Die Eingabe selektiert man mittels -i (Image directory) oder -c (Kamera). Außerdem ist die Angabe der gewünschten Operation erforderlich. Man startet in der Regel bei angeschlossener Kamera mit:
emeocv -c0 -a -s10 -vINFO
Das dient zum Justieren von Kamera und Licht. Es gibt das gerade aufgenommene Bild in einem Fenster aus. Der Benutzer kann mit den Tasten r und p zwischen dem Original und dem per ImageProcessor::process() verarbeiteten Bild umschalten. Mittels
emeocv -c0 -o images -s10000
lässt sich das Verzeichnis images mit von der Kamera aller 10 Sekunden aufgenommenen Bildern befüllen. Diese Bilder kann man nun offline inspizieren:
emeocv -i images -a -s0 -vINFO
Ziel ist, eine korrekte Segmentierung der einzelnen Ziffern des Zählers zu erreichen, wie sie in Abb. 7 zu sehen ist. Das erreicht man in erster Linie durch Modifikation der Konfigurationsparameter in config.yml. Die Parameter sind nicht dokumentiert, ein grundsätzliches Verständnis der Arbeitsweise und der Blick in den Sourcecode sind daher unabdingbare Voraussetzung für diesen Schritt!
Bei Erfolg ist es an der Zeit, den OCR zu trainieren:
emeocv -i images -l
Es öffnen sich zwei Fenster. Im großen sieht man das originale Image, im kleineren - leicht zu übersehenden - erscheint die zu trainierende Ziffer (Abb. 10).

Das Trainingsergebnis überprüft man mit:
emeocv -i images -t -s0
Für den normalen Betrieb legt man als erstes wie beschrieben die Datenbank an. Das Erfassungsprogramm läuft idealerweise im Hintergrund:
nohup emeocv -c0 -w -s10000 -vINFO &
Mit -s10000 erfolgt die Messwerterfassung aller 10 Sekunden. Damit lässt man der CPU des Raspberry Pi genügend Zeit für andere Aufgaben. Zu lang sollten die Pausen aber nicht sein, denn dann erhöht sich die Wahrscheinlichkeit, dass eine unvollständige Ziffer an der letzten Zählerstelle steht und keine korrekte Erkennung möglich ist.
Die Option -v steuert die Ausgabe von Nachrichten in die Logdatei emeocv.log. Auf das Logging geht der vorliegende Artikel nicht ein, die zugrundeliegenden Techniken und Frameworks (hier: log4cpp) sollten bekannt sein.
Fazit
Ein nach dem beschriebenen Verfahren aufgebauter Prototyp arbeitet seit einigen Wochen auf einem Raspberry Pi Model B und erfüllt den Anwendungszweck «Monitoring des Stromverbrauchs in einem Privathaushalt» zufriedenstellend. Bestechend ist der geringe Hardwareaufwand, neben dem Raspberry Pi benötigt man nur noch eine einfache USB-Webcam. Der spannende Teil der Verarbeitung ist komplett in Software realisiert. Die Hauptarbeit - Bilderfassung, -verarbeitung und Zeichenerkennung - leistet dabei OpenCV.
Diese Veröffentlichung soll Interessierte zu weiteren Versuchen anregen - über entsprechendes Feedback würde ich mich sehr freuen! Keinesfalls handelt es sich hierbei um eine Schritt-für-Schritt Anleitung oder gar ein fertiges Programm für den Endanwender. Dazu müssten noch viele weitere Algorithmen implementiert werden, wie zum Beispiel mehr Toleranz gegenüber wechselnden Lichtverhältnissen, automatische Bestimmung und Justierung von Konfigurationsparametern und eine bessere Zeichenerkennung für unterschiedliche Ziffertypen.
Interessante Links
- emeocv - Repository auf Github
- OpenCV
- Raspberry Pi Wiki bei eLinux.org
- Raspberry Pi Foundation
- RRDtool - OpenSource Datenerfassungs- und -visualisierungstool